Brief
Other than a mass of download links, this post also contains pretty pictures and confusing numbers which shows the break down of statistics regarding 17 wordlists. These wordlists, which the original source(s) can be found online, have been 'analysed', 'cleaned' and then 'sorted', for example:
Merged each 'collection' into one file (minus the 'readmes' files)
Removed leading & trailing spaces & tabs
Converted all 'new lines' to 'Unix' format
Removed non-printable characters
Removed HTML tags (Complete and common incomplete tags)
Removed (common domains) email addresses
Removed duplicate entries
How much would be used if they were for 'cracking WPA'(Between 8-63 characters)
It may not sound a lot - but after the process, the size of most wordlists are considerably smaller!
Method
Before getting the the results, each wordlist has been sorted differently rather than 'case sensitive A-Z'.
Each wordlist was:
Split into two parts - 'Single or two words' and 'multiple spaces'.
Sorted by the amount of times the word was duplicated - Therefore higher up the list, the more common the word is.
Sorted again by 'in-case sensitive A-Z'.
Joined back together - Single or two words at the start.
The reason for splitting into two parts was that 'most' passwords are either one or two words (containing one space in them). Words which have multiple spaces are mainly due to 'mistakes' with when/how the wordlists was created. So having them lower down, should increases the speed the password is discovered, without losing any possibility.
The justification of sorting by duplicated amount was the more common the word is, the higher the chance the word would be used! If you don't like this method, you can sort it yourself back to case sensitive A-Z, however it can't be sorted how it was - due to the lists not having (hopefully) any duplicates in them!
When removing HTML tags and/or email addresses, it doesn't mean that it wasn't effective. If the word has contained some HTML tags and it was still unique afterwords, it wouldn't change the line numbers, it would improve the wordlist & it still could be unique It is also worth mentioning, due to a general rule of 'search & replace', it COULD of removed a few false positives. It is believed that the amount removed to the predicted estimated amount is worth it. For example instead of having three passwords like below, it would be more worth while to have just the two passwords:
user1@company.com:password1
user2@company.com:password1
user3@company.com:password2
Download links for each collection which has been 'cleaned' is in the table below along with the results found and graphs. '17-in-1' is the combination of the results produced from each of the 17 collections. The extra addition afterwords (18-in-1), is a mixture of random wordlists (Languages (AIO), Random & WPA/WPA2) which I have accumulated. You can view & download them here (along with all the others!). '18-in-1 [WPA]', is a 'smaller' version of 18-in-1, with JUST words between 8-63 characters.
Source
UPDATE: Will re-upload soon
Collection Name (Original Source)Lines & Size (Extracted / Compressed)DownloadMD5Collection of Wordlist v.2 374806023 (3.9GB / 539MB) Part 1, Part 2, Part 3 5510122c3c27c97b2243208ec580cc67
HuegelCDC 53059218 (508MB / 64MB) Part 1 52f42b3088fcb508ddbe4427e8015be6
Naxxatoe-Dict-Total-New 4239459985 (25GB / 1.1GB) Part 1, Part 2, Part 3 Part 4, Part 5, Part 6 e52d0651d742a7d8eafdb66283b75e12
Purehates Word list 165824917 (1.7GB / 250MB) Part 1, Part 2 c5dd37f2b3993df0b56a0d0eba5fd948
theargonlistver1 4865840 (52MB / 15MB) Part 1 b156e46eab541ee296d1be3206b0918d
theargonlistver2 46428068 (297MB / 32MB) Part 1 41227b1698770ea95e96b15fd9b7fc6a
theargonlistver2-v2 (word.lst.s.u.john.s.u.200) 244752784 (2.2GB / 219MB) Part 1, Part 2 36f47a35dd0d995c8703199a09513259
WordList Collection 472603140 (4.9GB / 1.4GB) Part 1, Part 2, Part 3, Part 4, Part 5, Part 6, Part 7 a76e7b1d80ae47909b5a0baa4c414194
wordlist-final 8287890 (80MB / 19MB) Part 1 db2de90185af33b017b00424aaf85f77
wordlists-sorted 65581967 (687MB / 168MB) Part 1 2537a72f729e660d87b4765621b8c4bc
wpalist 37520637 (422MB / 66MB) Part 1 9cb032c0efc41f2b377147bf53745fd5
WPA-PSK WORDLIST (40 MB) 2829412 (32MB / 8.7MB) Part 1 de45bf21e85b7175cabb6e41c509a787
WPA-PSK WORDLIST 2 (107 MB) 5062241 (55MB / 15MB) Part 1 684c5552b307b4c9e4f6eed86208c991
WPA-PSK WORDLIST 3 Final (13 GB) 611419293 (6.8GB / 1.4GB) Part 1, Part 2, Part 3, Part 4, Part 5, Part 6, Part 7 58747c6dea104a48016a1fbc97942c14
-=Xploitz=- Vol 1 - PASSWORD DVD 100944487 (906MB / 109MB) Part 1 38eae1054a07cb894ca5587b279e39e4
-=Xploitz=- Vol 2 - Master Password Collection 87565344 (1.1GB / 158MB) Part 1 53f0546151fc2c74c8f19a54f9c17099
-=Xploitz Pirates=- Masters Password Collection #1! -- Optimized 79523622 (937MB / 134MB) Part 1 6dd2c32321161739563d0e428f5362f4
17-in-1 5341231112 (37GB / 4.5GB) Part 1 - Part 24 d1f8abd4cb16d2280efb34998d41f604
18-in-1 5343814622 (37GB / 4.5GB) Part 1 - Part 24 aee6d1a230fdad3b514a02eb07a95226
18-in-1 [WPA Edition] 1130701596 (12.6GB / 2.9GB) Part 1 - Part 15 425d47c549232b62dbb0e71b8394e9d9
Results
Table 1 - Raw Data
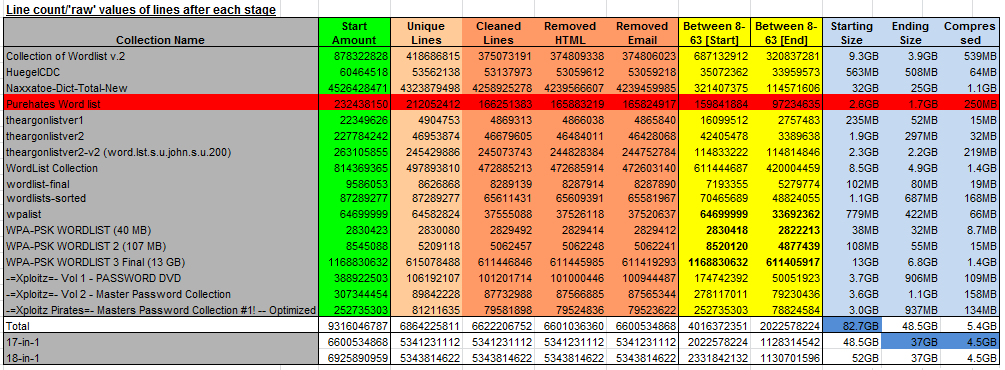
MEANT for WPA
A few notes about the results:
In the tables - 'Purehates' wordlist is corrupt and towards the end, it contains 'rubbish' (non-printable characters). Which is why it is highlighted red, as it isn't complete. I was unable to find the original.
Table 3 which summarizes the results - shows that 57% of the 17 collections are unique. Therefore 43% of it would be wasted due to duplication if it was tested - that's a large amount of extra un-needed attempts!
In graph 2 - Only one collection was 100% 'unique', which means most of the collections sizes have been reduced.
In graph 5 - which is for showing how effective it would be towards cracking WPA. The four wordlists which were 'meant' for WPA, are in red.
In a few of the 'readme' file (which wasn't included when merging), several of them claimed to of have duplicates removed. However, unless the list is sorted, the bash program 'uniq', wouldn't remove the duplicates. By piping the output of sort, uniq should then remove the duplicates. However, using sort takes time, and with a bit of 'awk fu', awk '!x[$0]++ [filename]', removes the need to sort.
For example:
Valueuniqsort / uniq or awk '!x[$0]++'word1,word2,word2,word3 word1,word2,word3 word1,word2,word3
word1,word2,word2,word3,word1 word1,word2,word3,word1 word1,word2,word3
word1,word2,word1,word1,word2,word3,word1 word1,word2,word1,word2,word3,word1 word1,word2,word3
Commands
The commands used were:
Step By Step
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
# Merging rm -vf CREADME CHANGELOG* readme* README* stage* echo "Number of files:" `find . -type f | wc -l` cat * > /tmp/aio-"${PWD##*/}".lst && rm * && mv /tmp/aio-"${PWD##*/}".lst ./ && wc -l aio-"${PWD##*/}".lst file -k aio-"${PWD##*/}".lst # Uniq Lines cat aio-"${PWD##*/}".lst | sort -b -f -i -T "$(pwd)/" | uniq > stage1 && wc -l stage1 # "Clean" Lines tr '\r' '\n' < stage1 > stage2-tmp && rm stage1 && tr '# Merging rm -vf CREADME CHANGELOG* readme* README* stage* echo "Number of files:" `find . -type f | wc -l` cat * > /tmp/aio-"${PWD##*/}".lst && rm * && mv /tmp/aio-"${PWD##*/}".lst ./ && wc -l aio-"${PWD##*/}".lst file -k aio-"${PWD##*/}".lst # Uniq Lines cat aio-"${PWD##*/}".lst | sort -b -f -i -T "$(pwd)/" | uniq > stage1 && wc -l stage1 # "Clean" Lines tr '\r' '\n' < stage1 > stage2-tmp && rm stage1 && tr '
' ' ' < stage2-tmp > stage2-tmp1 && rm stage2-tmp && tr -cd '-6' < stage2-tmp1 > stage2-tmp && rm stage2-tmp1 cat stage2-tmp | sed "s/ */ /gI;s/^[ \t]*//;s/[ \t]*$//" | sort -b -f -i -T "$(pwd)/" | uniq > stage2 && rm stage2-* && wc -l stage2 # Remove HTML Tags htmlTags="a|b|big|blockquote|body|br|center|code|del|div|em|font|h[1-9]|head|hr|html|i|img|ins|item|li|ol|option|p|pre|s|small|span|strong|sub|sup|table|td|th|title|tr|tt|u|ul" cat stage2 | sed -r "s/<[^>]*>//g;s/^\w.*=\"\w.*\">//;s/^($htmlTags)>//I;s/<\/*($htmlTags)$//I;s/&*/&/gI;s/"/\"/gI;s/'/'/gI;s/'/'/gI;s/</
stage3 && wc -l stage3 && rm stage2 # Remove Email addresses cat stage3 | sed -r "s/\w.*\@.*\.(ac|ag|as|at|au|be|bg|bill|bm|bs|c|ca|cc|ch|cm|co|com|cs|de|dk|edu|es|fi|fm|fr|gov|gr|hr|hu|ic|ie|il|info|it|jo|jp|kr|lk|lu|lv|me|mil|mu|net|nil|nl|no|nt|org|pk|pl|pt|ru|se|si|tc|tk|to|tv|tw|uk|us|ws|yu)

//gI" | sort -b -f -i -T "$(pwd)/" | uniq > stage4 && wc -l stage4 && rm stage3 # Misc pw-inspector -i aio-"${PWD##*/}".lst -o aio-"${PWD##*/}"-wpa.lst -m 8 -M 63 ; wc -l aio-"${PWD##*/}"-wpa.lst && rm aio-"${PWD##*/}"-wpa.lst pw-inspector -i stage4 -o stage5 -m 8 -M 63 ; wc -l stage5 7za a -t7z -mx9 -v200m stage4.7z stage4 du -sh * ' ' ' < stage2-tmp > stage2-tmp1 && rm stage2-tmp && tr -cd '1250-76' < stage2-tmp1 > stage2-tmp && rm stage2-tmp1 cat stage2-tmp | sed "s/ */ /gI;s/^[ \t]*//;s/[ \t]*$//" | sort -b -f -i -T "$(pwd)/" | uniq > stage2 && rm stage2-* && wc -l stage2 # Remove HTML Tags htmlTags="a|b|big|blockquote|body|br|center|code|del|div|em|font|h[1-9]|head|hr|html|i|img|ins|item|li|ol|option|p|pre|s|small|span|strong|sub|sup|table|td|th|title|tr|tt|u|ul" cat stage2 | sed -r "s/<[^>]*>//g;s/^\w.*=\"\w.*\">//;s/^($htmlTags)>//I;s/<\/*($htmlTags)$//I;s/&*/&/gI;s/"/\"/gI;s/'/'/gI;s/'/'/gI;s/</ stage3 && wc -l stage3 && rm stage2 # Remove Email addresses cat stage3 | sed -r "s/\w.*\@.*\.(ac|ag|as|at|au|be|bg|bill|bm|bs|c|ca|cc|ch|cm|co|com|cs|de|dk|edu|es|fi|fm|fr|gov|gr|hr|hu|ic|ie|il|info|it|jo|jp|kr|lk|lu|lv|me|mil|mu|net|nil|nl|no|nt|org|pk|pl|pt|ru|se|si|tc|tk|to|tv|tw|uk|us|ws|yu)
//gI" | sort -b -f -i -T "$(pwd)/" | uniq > stage4 && wc -l stage4 && rm stage3 # Misc pw-inspector -i aio-"${PWD##*/}".lst -o aio-"${PWD##*/}"-wpa.lst -m 8 -M 63 ; wc -l aio-"${PWD##*/}"-wpa.lst && rm aio-"${PWD##*/}"-wpa.lst pw-inspector -i stage4 -o stage5 -m 8 -M 63 ; wc -l stage5 7za a -t7z -mx9 -v200m stage4.7z stage4 du -sh *
AIO
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
rm -f stage* echo "Number of files:" `find . -type f | wc -l` cat * > /tmp/aio-"${PWD##*/}".lst && rm * && mv /tmp/aio-"${PWD##*/}".lst ./ tr '\r' '\n' < aio-"${PWD##*/}".lst > stage1-tmp && tr 'rm -f stage* echo "Number of files:" `find . -type f | wc -l` cat * > /tmp/aio-"${PWD##*/}".lst && rm * && mv /tmp/aio-"${PWD##*/}".lst ./ tr '\r' '\n' < aio-"${PWD##*/}".lst > stage1-tmp && tr '
' ' ' < stage1-tmp > stage1-tmp1 && tr -cd '-6' < stage1-tmp1 > stage1-tmp && mv stage1-tmp stage1 && rm stage1-* # End Of Line/New Line & "printable" htmlTags="a|b|big|blockquote|body|br|center|code|del|div|em|font|h[1-9]|head|hr|html|i|img|ins|item|li|ol|option|p|pre|s|small|span|strong|sub|sup|table|td|th|title|tr|tt|u|ul" cat stage1 | sed -r "s/ */ /gI;s/^[ \t]*//;s/[ \t]*$//;s/<[^>]*>//g;s/^\w.*=\"\w.*\">//;s/^($htmlTags)>//I;s/<\/*($htmlTags)$//I;s/&*/&/gI;s/"/\"/gI;s/'/'/gI;s/'/'/gI;s/</
stage2 && rm stage1 sort -b -f -i -T "$(pwd)/" stage2 > stage3 && rm stage2 grep -v " * .* " stage3 > stage3.1 grep " * .* " stage3 > stage3.4 #grep -v " * .* \| " stage3 > stage3.1 # All one or two words #grep " * .* " stage3 | grep -v " " > stage3.2 # All 3+ words #grep " * .* " stage3 | grep " " > stage3.3 # All multiple spacing words rm stage3 for fileIn in stage3.*; do # Place one or two words at the start, cat "$fileIn" | uniq -c -d > stage3.0 # Sort, then find dups (else uniq could miss out a few values if the list wasn't in order e.g. test1 test2 test3, test2, test4) sort -b -f -i -T "$(pwd)/" -k1,1r -k2 stage3.0 > stage3 && rm stage3.0 # Sort by amount of dup times (9-0) then by the value (A-Z) sed 's/^ *//;s/^[0-9]* //' stage3 >> "${PWD##*/}"-clean.lst && rm stage3 # Remove "formatting" that uniq adds (Lots of spaces at the start) cat "$fileIn" | uniq -u >> "${PWD##*/}"-clean.lst # Sort, then add unique values at the end (A-Z) rm "$fileIn" done rm -f stage* #aio-"${PWD##*/}".lst #7za a -t7z -mx9 -v200m "${PWD##*/}".7z "${PWD##*/}".lst wc -l "${PWD##*/}"-clean.lst md5sum "${PWD##*/}"-clean.lst ' ' ' < stage1-tmp > stage1-tmp1 && tr -cd '1250-76' < stage1-tmp1 > stage1-tmp && mv stage1-tmp stage1 && rm stage1-* # End Of Line/New Line & "printable" htmlTags="a|b|big|blockquote|body|br|center|code|del|div|em|font|h[1-9]|head|hr|html|i|img|ins|item|li|ol|option|p|pre|s|small|span|strong|sub|sup|table|td|th|title|tr|tt|u|ul" cat stage1 | sed -r "s/ */ /gI;s/^[ \t]*//;s/[ \t]*$//;s/<[^>]*>//g;s/^\w.*=\"\w.*\">//;s/^($htmlTags)>//I;s/<\/*($htmlTags)$//I;s/&*/&/gI;s/"/\"/gI;s/'/'/gI;s/'/'/gI;s/</ stage2 && rm stage1 sort -b -f -i -T "$(pwd)/" stage2 > stage3 && rm stage2 grep -v " * .* " stage3 > stage3.1 grep " * .* " stage3 > stage3.4 #grep -v " * .* \| " stage3 > stage3.1 # All one or two words #grep " * .* " stage3 | grep -v " " > stage3.2 # All 3+ words #grep " * .* " stage3 | grep " " > stage3.3 # All multiple spacing words rm stage3 for fileIn in stage3.*; do # Place one or two words at the start, cat "$fileIn" | uniq -c -d > stage3.0 # Sort, then find dups (else uniq could miss out a few values if the list wasn't in order e.g. test1 test2 test3, test2, test4) sort -b -f -i -T "$(pwd)/" -k1,1r -k2 stage3.0 > stage3 && rm stage3.0 # Sort by amount of dup times (9-0) then by the value (A-Z) sed 's/^ *//;s/^[0-9]* //' stage3 >> "${PWD##*/}"-clean.lst && rm stage3 # Remove "formatting" that uniq adds (Lots of spaces at the start) cat "$fileIn" | uniq -u >> "${PWD##*/}"-clean.lst # Sort, then add unique values at the end (A-Z) rm "$fileIn" done rm -f stage* #aio-"${PWD##*/}".lst #7za a -t7z -mx9 -v200m "${PWD##*/}".7z "${PWD##*/}".lst wc -l "${PWD##*/}"-clean.lst md5sum "${PWD##*/}"-clean.lst
If you're wanting to try this all out for your self, you can find some more wordlists here:
http://www.skullsecurity.org/wiki/index.php/Passwords
http://trac.kismac-ng.org/wiki/wordlists
http://hashcrack.blogspot.com/p/wordlist-downloads_29.html
http://packetstormsecurity.org/Crackers/wordlists/
http://0x80.org/wordlist/
http://dictionary-thesaurus.com/wordlists.html
http://www.outpost9.com/files/WordLists.html
http://www.openwall.com/passwords/wordlists/
http://dictionary-thesaurus.com/Wordlists.html
http://en.wikipedia.org/wiki/Wikipedia_database#Where_do_I_get... &
http://blog.sebastien.raveau.name/2009/03/cracking-passwords-with-wikipedia.html
http://www.isdpodcast.com/resources/62k-common-passwords/
Moving forwards
As mentioned at the start, whilst having gigabytes worth of wordlists may be good and all... having a personalised/specific/targeted wordlist is great. PaulDotCom (great show by the way), did just that a while back.
As the password has to be in the wordlist, and if it doesn't have the correct password you could try crunch (or L517 for windows) to generate your own. For a few good tutorials on how to use crunch, check here and here (I highly recommend ADayWithTape's blog).
As waiting for a mass of words to be tried takes some time - it could be sped up by 'pre-hashing'. For example this WPA-PSK is vulnerable, however WPA-PSK is 'Salted' (By using the SSID as the salt). This means that each pre-hashes table is only valid for THAT salt/SSID. This isn't going to turn into another 'How to crack WPA', as its already been done. It was just mentioned due to this and this could help speed up the process.
Instead of brute forcing your way in, by 'playing it smart', it could be possible to generate/discover the password instead. This works if the algorithm has a weakness, for example here, or if the system is poor, for example here. However, finding a weakness might take longer than trying a wordlist (or three!).
When compiling all of this, I came across this, Most 'professional password guessers' known:
There is a 50 percent chance that a user's password will contain one or more vowels.
If it contains a number, it will usually be a 1 or 2, and it will be at the end.
If it contains a capital letter, it will be at the beginning, followed by a vowel.
The average person has a working vocabulary of 50,000 to 150,000 words, and they are likely to be used in the password.
Women are famous for using personal names in their passwords, and men opt for their hobbies.
"Tigergolf" is not as unique as CEOs think.
Even if you use a symbol, an attacker knows which are most likely to appear: ~, !, @, #, $, %, &, and?.
When your password has to be 'least 8 characters long and include at least one capital' it doesn't mean: 'MickeyMinniePlutoHueyLouieDeweyDonaldGoofyLondon'. And for the people that made it this far down, here is a 'riddle' on the the subject of passwords.
via: www.foulscode.com
 GRadmin
GRadmin